Tutorial
This tutorial will walk you through all of the major components of a censaurus workflow. The major steps highlighted are:
The goal of this tutorial is to create a detailed choropleth map of the Northeast Region of the United States, where geographic areas are colored by the proportion of the men in those areas who are 65 years or older.
Let’s begin!
Choosing a dataset
censaurus has built in support for a number of popular Census datasets, including:
Decennial Census (general):
Decennial
Decennial Census Redistricting Data:
DecennialPLDecennial Census Summary File 1:
DecennialSF1Decennial Census Summary File 2:
DecennialSF2American Community Survey Census (general):
ACS
American Community Survey 1-Year Data:
ACS1American Community Survey 1-Year Supplemental Data:
ACSSupplementalAmerican Community Survey 3-Year Data:
ACS3American Community Survey 5-Year Data:
ACS5American Community Survey Migration Flows:
ACSFlowsAmerican Community Survey Language Statistics:
ACSLanguagePublic Use Microdata Sample (general):
PUMSCurrent Population Survey (general):
CPSEconomic Census (general):
Economic
Economic Census Key Statistics:
EconomicKeyStatisticsPopulation Estimates (general):
EstimatesPopulation Projections (general):
Projections
Note
Each of these datasets has its own set of extra parameters. For example, initializing the American Community Survey 1-Year Data class (ACS1) requires a year (defaults to 2021) and an extension (defaults to None). In the ACS1 case, the extension controls what “table” you get: None indicates the Detailed Tables, while subject, profile, cprofile, and spp indicate various other tables. Please consult the documentation for your particular dataset (and potentially the Census’s Available APIs page) to see what parameters are required and how they will impact your request.
censaurus also supports all other datasets available on the Census API (see the Census’s Available APIs page for a full list). To request data from a dataset not natively supported by censaurus, simply instantiate the base Dataset class with the necessary parameters.
Each dataset has its own use case. For example, the Decennial Census is typically used in studies of apportionment and representation and is only carried out once every 10 years. The Current Population Survey, on the other hand, is a monthly survey with an emphasis on employment. If you can’t decide what dataset is right for you, check out the Census’s programs and surveys page for an overview of each dataset.
For our particular use case — mapping the age-breakdown of Census tracts in the U.S. — we’ll use the American Community Survey 5-Year Data because it has the demographic variables we need and because it has more granular geographic coverage than the 1- and 3-Year ACS datasets.
Therefore, our workflow starts by initializing an ACS5 object (we can use the default parameters).
>>> from censaurus import ACS5
>>> acs = ACS5()
Finding relevant variables
Now that we have our dataset picked out, let’s find the variables we need. censaurus has tools to help us do just that.
In general, censaurus stores sets of variables as VariableCollection objects. The collection of variables that are available from a particular dataset can be found at the Dataset.variables property. Let’s inspect the VariableCollection associated with our acs dataset:
>>> acs.variables
VariableCollection of 27927 variables:
AIANHH
group: N/A
concept: None
path: [geography]
AIHHTL
group: N/A
concept: None
path: [geography]
...
in
group: N/A
concept: census api geography specification
path: [census api geography specification -> census api fips 'in' clause]
ucgid
group: N/A
concept: census api geography specification
path: [census api geography specification -> uniform census geography identifier clause]
That’s a lot of variables! Certainly too many to sift through by hand. Thankfully, the VariableCollection class comes with some handy tools to filter and visualize Census variables. To find age- and sex-related variables within acs.variables, there are a few approaches we could take.
First, we could try filtering our variables by some specific search terms. Let’s try searching for variables whose concepts contain the word “age” and the word “sex”.
>>> acs.variables.filter_by_term(term=['age', 'sex'], by='concept')
VariableCollection of 3417 variables:
B01001A_001E
group: B01001A
concept: sex by age (white alone)
path: [sex by age (white alone) -> estimate -> total]
B01001A_002E
group: B01001A
concept: sex by age (white alone)
path: [sex by age (white alone) -> estimate -> total -> male]
...
C27009_020E
group: C27009
concept: va health care by sex by age
path: [va health care by sex by age -> estimate -> total -> female -> 65 years and over -> with va health care]
C27009_021E
group: C27009
concept: va health care by sex by age
path: [va health care by sex by age -> estimate -> total -> female -> 65 years and over -> no va health care]
Uh oh! That’s still a lot of variables. Let’s try a different approach. The Census categorizes variables into groups, and censaurus lets you search through those, too, by using the Dataset.groups attribute.
>>> acs.groups.filter_by_term(term=['age', 'sex'])
GroupCollection of 98 groups:
B01001
concept: sex by age
variables (49): [B01001_001E, ..., B01001_049E]
B01001A
concept: sex by age (white alone)
variables (31): [B01001A_001E, ..., B01001A_031E]
...
C27008
concept: tricare/military health coverage by sex by age
variables (21): [C27008_001E, ..., C27008_021E]
C27009
concept: va health care by sex by age
variables (21): [C27009_001E, ..., C27009_021E]
Perfect! It seems like that first group — B01001 (sex by age) — is exactly what we need.
Let’s inspect the variables in the B01001 group using another filtering method, paired with the network visualization tools built right into censaurus.
>>> acs.variables.filter_by_group(group='B01001').visualize()
Note
By default, running the above code will open this network visualization in your default browser.
Each node in the network above corresponds to a unique Census variable. You can hover over a node to learn more about the variable. Variables are connected when one variable is a subset — or a child — of another. For example, in the network above, the variables B01001_002E (total -> male) and B01001_003E (total -> male -> under 5 years old) are connected because the latter is a subset of the former.
After looking at our network of variables, it’s clear that we want all of the variables that look something like (total -> male -> xxx). In other words, we want the children of B01001_002E, the (total -> male) variable. To get those variables, we can simply call:
>>> acs.variables.children_of(variable='B01001_002E')
VariableCollection of 23 variables:
B01001_003E
group: B01001
concept: sex by age
path: [sex by age -> estimate -> total -> male -> under 5 years]
B01001_004E
group: B01001
concept: sex by age
path: [sex by age -> estimate -> total -> male -> 5 to 9 years]
...
B01001_024E
group: B01001
concept: sex by age
path: [sex by age -> estimate -> total -> male -> 80 to 84 years]
B01001_025E
group: B01001
concept: sex by age
path: [sex by age -> estimate -> total -> male -> 85 years and over]
Great! It looks like we’ve found the variables we need. Let’s save them and move on to picking a geographic hierarchy.
>>> male_age_vars = acs.variables.children_of(variable='B01001_002E')
Picking a geography hierarchy
The Census provides data at various levels of geographic specification. Some examples include region, division, state, county, congressional district, school district, etc.
Warning
The available geographies depend significantly on your specified dataset.
Let’s check out the available geographies for our dataset using the Dataset.geographies property:
>>> acs.geographies.to_df()
name level requirements
0 us 010 []
1 region 020 []
2 division 030 []
3 state 040 []
4 county 050 [state]
.. ... ... ...
82 public use microdata area 795 [state]
83 zip code tabulation area 860 []
84 school district (elementary) 950 [state]
85 school district (secondary) 960 [state]
86 school district (unified) 970 [state]
[87 rows x 3 columns]
We can also explore supported geographies the same way we explore variables. This time, let’s try out a hierarchical view:
>>> acs.geographies.visualize(hierarchical=True)
The relationships between nodes here is similar to that of variables in the previous network visualization. Geographies are connected when one geography is a geographic subset of another. For example, the Census allows you to query counties within states, so state and county are connected (the former is the parent of the latter).
Because we want to make a detailed plot, we probably don’t want to go with states or counties (these areas are too big). A good middle ground between detail and avoiding clutter is Census tracts. There are around 84,000 Census tracts in the country; on average, tracts have about 4000 people. Let’s see if that geography hierarchy is available for our dataset.
>>> acs.geographies.get(name="tract")
tract (140)
requires: ['state', 'county']
wildcards: ['county']
path: [state -> county -> tract]
Note
Occasionally, there are multiple geography hierarchies referred to by the same name. For example, counties within states and counties within Congressional Districts are both referred to as county. In this case, the result of the get() call would be a list.
We’re in luck! The tract hierarchy is available for our dataset, so we can proceed.
Requesting data
Next up is actually requesting data from the Census. The Dataset class has 16 convenience methods for requesting data at various geographic specifications. In our case, we will use the Dataset.tracts() built-in function.
Note
There is also the Dataset.other_geography() function for requesting a geographic specification that is not natively supported.
The Dataset.tracts() method, and all Dataset methods like it, ask for a few parameters. The first is the within parameter. The within parameter acts as a sort of boundary for our data — we can use it to subset our data geographically.
For this task, we want to only include Census tracts that lay within the Northeast Region of the United States. To achieve this, we need to set the within parameter equal to an Area object that represents the Northeast Region. We can create such an Area object by accessing the Dataset.areas property and calling the .region() function:
>>> northeast = acs.areas.region('Northeast')
successfully matched 'Northeast' to 'Northeast Region' (GEOID = 1) in layer 'Census Regions'
Let’s plot the northeast object to see what we’ve got:
>>> import matplotlib.pyplot as plt
>>> northeast.plot()
>>> plt.show()
Looks like we got what we wanted!
The next parameter is the variables parameter — this tells censaurus what variables to request from the Census. Here, we can simply use the male_age_vars variable we saved earlier!
Note
The variables parameter is quite versatile. You can give it a VariableCollection or a list of variable names or some combination of those. For example, you could do the following:
>>> acs.states(variables=
acs.variables.filter_by_group("B01001") +
acs.variables.filter_by_group("B01001A") +
["B01001B_001E", "B01001B_002E"]
)
You can also give it a dictionary of variable names and what you want those variable names to be renamed to when the data is returned.
And with that, we’re good to go! There are some other parameters — namely, groups, return_geometry, area_threshold, and extra_census_params — but we can leave those all as their defaults for now. Let’s try requesting some data!
>>> data = acs.tracts(within=northeast, variables=male_age_vars)
>>> data
B01001_003E B01001_004E B01001_005E B01001_006E ... GEO_ID state county tract
0 32 15 24 8 ... 1400000US23001010100 23 001 010100
1 40 111 381 68 ... 1400000US23001010200 23 001 010200
2 121 96 69 47 ... 1400000US23001010300 23 001 010300
3 26 49 24 25 ... 1400000US23001010400 23 001 010400
4 47 80 77 14 ... 1400000US23001010500 23 001 010500
... ... ... ... ... ... ... ... ... ...
14699 81 102 95 56 ... 1400000US44009051502 44 009 051502
14700 41 0 13 64 ... 1400000US44009051503 44 009 051503
14701 34 12 21 74 ... 1400000US44009051504 44 009 051504
14702 0 0 0 0 ... 1400000US44009990100 44 009 990100
14703 0 0 0 0 ... 1400000US44009990200 44 009 990200
[14704 rows x 28 columns]
Looking good! We got the data we wanted for all Census tracts in the Northeast region of the United States.
Note
You may have noticed that tracts within regions is not a supported geographic hierarchy for this dataset — as far as I’m aware, it’s not a supported hierarchy for any Census dataset. But thanks to censaurus, that’s totally okay. Using the within parameter, you can get any geographic level within any other geographic level. Counties within a state? Sure, that’s easy (and already supported by the Census). But metropolitan statistical areas within Congressional Districts? That’s just as easy, even though it’s not supported by the Census! Thanks to how censaurus internally handles geometry, you can even request block-level data for the entire United States (it just might take a few minutes) without any extra work! Go wild!
Finally, let’s try flipping the return_geometry flag to True because we’ll need geometry to make maps.
>>> data = acs.tracts(within=northeast, variables=male_age_vars, return_geometry=True)
>>> data
B01001_003E B01001_004E B01001_005E B01001_006E ... state county tract geometry
0 84 84 80 80 ... 42 001 030101 POLYGON ((-77.14596 40.06185, -77.14186 40.064...
1 0 0 178 79 ... 42 001 030103 POLYGON ((-77.06352 39.97945, -77.06324 39.979...
2 76 123 218 30 ... 42 001 030104 POLYGON ((-77.08880 39.95342, -77.08833 39.953...
3 160 279 332 120 ... 42 001 030200 POLYGON ((-77.23750 40.02674, -77.23310 40.027...
4 78 86 172 105 ... 42 001 030300 POLYGON ((-77.41007 39.98776, -77.40994 39.987...
... ... ... ... ... ... ... ... ... ...
14699 51 75 78 35 ... 34 041 032101 POLYGON ((-75.09420 40.72385, -75.09403 40.723...
14700 93 151 281 226 ... 34 041 032102 POLYGON ((-75.14311 40.69127, -75.14133 40.692...
14701 217 252 232 144 ... 34 041 032200 POLYGON ((-75.18760 40.71307, -75.18687 40.714...
14702 170 52 44 72 ... 34 041 032300 POLYGON ((-75.19225 40.62238, -75.19177 40.622...
14703 31 121 40 30 ... 34 041 032400 POLYGON ((-75.16415 40.65275, -75.16365 40.653...
[14704 rows x 29 columns]
Note
Now that we are asking for geometry, the .tracts() function call returns a geopandas.GeoDataFrame instead of a pandas.DataFrame.
With the data we were looking for, let’s try out some of the censaurus data cleaning tools to help us prepare for our final analysis.
Cleaning data
First of all, our data is almost unintelligible at the moment: we have no idea what the variables B01001_003E, B01001_004E, B01001_005E, etc. actually mean. To change those column names to more legible ones, we can use the Renamer tools that censaurus offers. These tools leverage the Variable and VariableCollection classes, as well as some custom censaurus pandas.DataFrame and pandas.Series accessors, to make renaming easier than ever. For this tutorial, let’s use the SIMPLE_RENAMER with the default parameters.
>>> from censaurus.rename import SIMPLE_RENAMER
>>> data = SIMPLE_RENAMER.rename(data)
>>> data
sex by age|total|male|0-5 sex by age|total|male|5-9 ... tract geometry
0 100 54 ... 010100 POLYGON ((-70.18673 42.02161, -70.18921 42.022...
1 79 192 ... 010206 POLYGON ((-70.06742 41.88727, -70.06689 41.888...
2 53 53 ... 010208 POLYGON ((-70.00152 41.96946, -70.00206 41.969...
3 11 31 ... 010304 POLYGON ((-69.93792 41.81583, -69.93869 41.815...
4 67 83 ... 010306 POLYGON ((-69.94688 41.84947, -69.94733 41.849...
... ... ... ... ... ...
14699 44 41 ... 966501 POLYGON ((-72.67563 43.23437, -72.67561 43.235...
14700 31 28 ... 966502 POLYGON ((-72.85907 43.30593, -72.85864 43.311...
14701 93 0 ... 966600 POLYGON ((-72.53963 43.24049, -72.53961 43.241...
14702 66 102 ... 966700 POLYGON ((-72.53679 43.34063, -72.53611 43.347...
14703 45 77 ... 966800 POLYGON ((-72.97063 43.87877, -72.97060 43.880...
[14704 rows x 29 columns]
That looks much better.
Next, while we want to know the proportion of men who are over 65 years and above, our data has age broken up into many more categories than that. The Census tells us the number of men who are 65-66, 67-69, 70-74, 75-79, 80-84, and 85+. To fix that, we can turn to the censaurus Regrouper tools. In this case, we’ll instantiate a AgeRegrouper object with our new desired age brackets and then regroup our data as follows.
>>> from censaurus.regroup import AgeRegrouper
>>> data = AgeRegrouper(age_brackets=['0-64', '65+']).regroup(data)
>>> data = SIMPLE_RENAMER.rename(data)
>>> data
sex by age|total|male|0-64 sex by age|total|male|65+ ... tract geometry
0 1636 405 ... 010100 POLYGON ((-70.18673 42.02161, -70.18921 42.022...
1 1568 440 ... 010206 POLYGON ((-70.06742 41.88727, -70.06689 41.888...
2 636 248 ... 010208 POLYGON ((-70.00152 41.96946, -70.00206 41.969...
3 805 473 ... 010304 POLYGON ((-69.93792 41.81583, -69.93869 41.815...
4 778 497 ... 010306 POLYGON ((-69.94688 41.84947, -69.94733 41.849...
... ... ... ... ... ...
14699 990 491 ... 966501 POLYGON ((-72.67563 43.23437, -72.67561 43.235...
14700 525 214 ... 966502 POLYGON ((-72.85907 43.30593, -72.85864 43.311...
14701 1841 525 ... 966600 POLYGON ((-72.53963 43.24049, -72.53961 43.241...
14702 1784 547 ... 966700 POLYGON ((-72.53679 43.34063, -72.53611 43.347...
14703 1133 440 ... 966800 POLYGON ((-72.97063 43.87877, -72.97060 43.880...
[14704 rows x 8 columns]
Finally, we’ll add a column to our dataset that has the variable of interest:
>>> data['proportion_65+'] = data['sex by age|total|male|65+']/(data['sex by age|total|male|0-64'] + data['sex by age|total|male|65+'])
Great! We’ve got the data we want in the format we want; time to finish with plotting!
Plotting data
Because we set return_geometry to True, censaurus automatically gives us back a geopandas.GeoDataFrame. This allows for quick and easy geographic plotting using the great geopandas plotting tools. To make the graph we set out to make, all we need to do is the following:
>>> data.plot(column='proportion_65+')
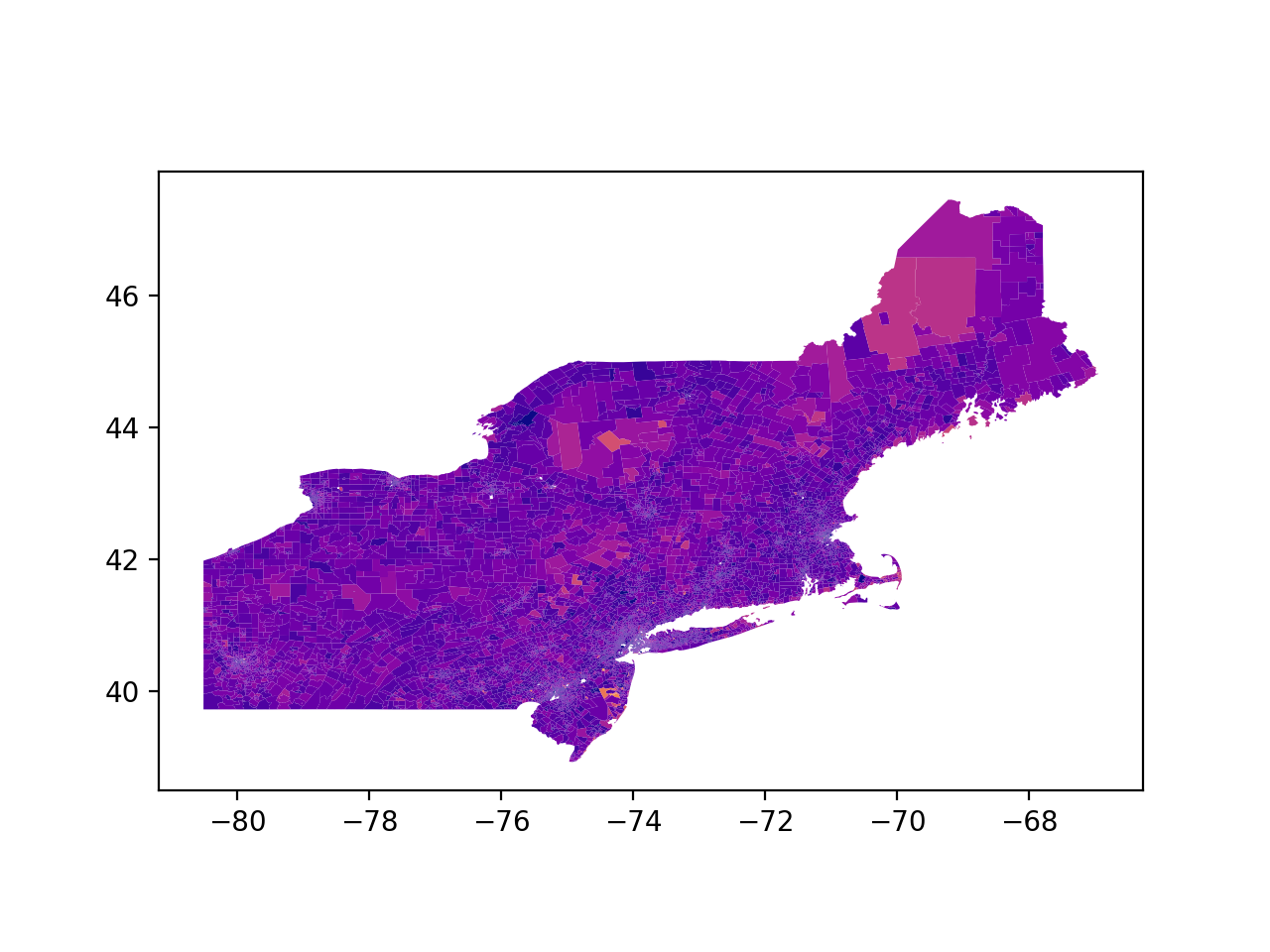
And that’s it! We have our plot of Census tracts in the Northeast Region of the United States, colored by the proportion of their male residents who are 65 years old or older. There are all sorts of other customization to clean up our visualization, but those are out of the scope of this tutorial.
Please check out the detailed documentation to answer any further questions!